

Photo by ThisisEngineering RAEng on Unsplash
SRE or why IT practices changed?
In the beginning, we were all developers with sysadmin, then DevOps now SRE... what is this about?


I'm an old geek and I used to say this to my team all the time; not because I love being old but because I think this is helping me today trying to understand why we are proposing some new methodologies or technologies. History is helping us to prevent past problems, experience in the IT world the same.
Today we are talking about SRE (Site Reliable Engineer) in many companies, and it is happening several years after the USA for the same practice. But we are not always applying it with a base knowledge (what problem we are solving with this?) and creating job titles because the "new generations" want this.
I will try to give here examples I had in my career to give a "why we are introducing SRE" (or DevOps before). If you are just looking for a complete guide to SRE I suggest you read one of the following ebooks sre.google/books. I read this one

and it is a very interesting lecture.
But, let's get back to my history.
In the beginning we had Dev and SysAdmin
When I started my IT career, the real one with a salary I mean, it was 17 years ago 😱😱. I was a simple developer. My job was to write a piece of code, let it working and that's all: someone else was in charge of building the final binary and some other teammates to put and run it in production.
The Silos IT: you have the best experts in each domain each one in charge about only a part of the IT environment, the dev, the CI engineer, the SysAdmin, what can be wrong? Problems here are coming in between the different roles. The developer team was configuring the dev laptop with a JVM which was not the one used for the build and in production (because it was a proprietary one, thanks to IBM 😠), the application server was not the same one, for the same reason and because the laptop resources were far from the production ones.
So sometimes the build was failing or not producing the same result (how many of you worked before the Java annotations were invented? What about XDoclet ?) and once in production, the software may have problems that the SysAdmin team was not able to fix. Because was not the Application server itself but maybe the application, maybe the build. How to find it out?
The classical example here, I had several times: after some days/weeks the application was failing/restarting and usually, it was related to the memory limit. So what the SysAdmin team could do?
- First step: add RAM. But this is just reducing the number of problems. Once a X applications still fail and trigger the duty.
- Second step: create a cronjob to auto restart the application and auto-fix the problem. 🤩😎
I know somebody of you is smiling because today we would not think of this solution anymore (I hope so 😅), but how the SysAdmin team can fix something that was not known by them? The application they were running was developed by the dev team (and built by the CI one). So? Monitoring. SysAdmin team installs tools to get data to try to understand and then forces the dev team to read the data and give them the solution. 🤯
DevOps practice
As things were not working well, we introduced something different which was trying to remove/reduce this no-mans-land between each role.
DevOps is a set of practices that combines software development (Dev) and IT operations (Ops). It aims to shorten the systems development life cycle and provide continuous delivery with high software quality.[1] DevOps is complementary with Agile software development; several DevOps aspects came from the Agile methodology.
We can define it differently: give more "power" to the developer team making the CI and System near the code, and to the ones creating it. But, in my opinion, things did not work as expected: DevOps move from practice to Job title; it was then about automating system installation (Ansible, Puppet, ...) and we tried to find a large different definition to something that wanted to be only a set of practices to fix the problem I described at the beginning.
Then it was the time about Docker: cool we can run on the dev laptop the same thing we will run in production and in the same way. No more it was running on my laptop. But moving to Docker without a real problem to fix, produced completely crazy things.
How can I save what changed within my Docker VM (😩)?
It is not like VMWare.
But, as Docker container was failing sometimes, and it was not starting back automatically, Kubernetes came to fix it. The orchestrator to manage them all. We moved from a simple system and simple problem to something more complex without really knowing why. (because for me K8s is fixing another problem than the one I was describing)
SRE to fix everything
Because DevOps failed, we introduce then something coming from US and Google, and if it is coming from Google it is surely working better 😅
Site reliability engineering (SRE) is a set of principles and practices[1] that incorporates aspects of software engineering and applies them to infrastructure and operations problems.[2] The main goals are to create scalable and highly reliable software systems.[2] Site reliability engineering is closely related to DevOps, a set of practices that combine software development and IT operations, and SRE has also been described as a specific implementation of DevOps.[2][3]
I guess reading the description we can all say: it is almost the same thing DevOps wanted to do.
What is (a little bit) changing is how we look at our production application: the important thing is to have an application providing a service for our customers and respecting the defined SLAs; automate everything to be fast in case of problems; observe everything to be able to take actions.
An example: a cart API that should answer in less than 20ms and with an uptime of 99,9%. These are our SLAs. The next step is to follow the production values; an easy game with just NGINX access logs, a big query and grafana. How many calls are not 2xx and how many are outside the 20ms required?
FYI Google is providing a cool set of tools for this: github.com/google/slo-generator. We are using it on all our applications and the results are really crazy.
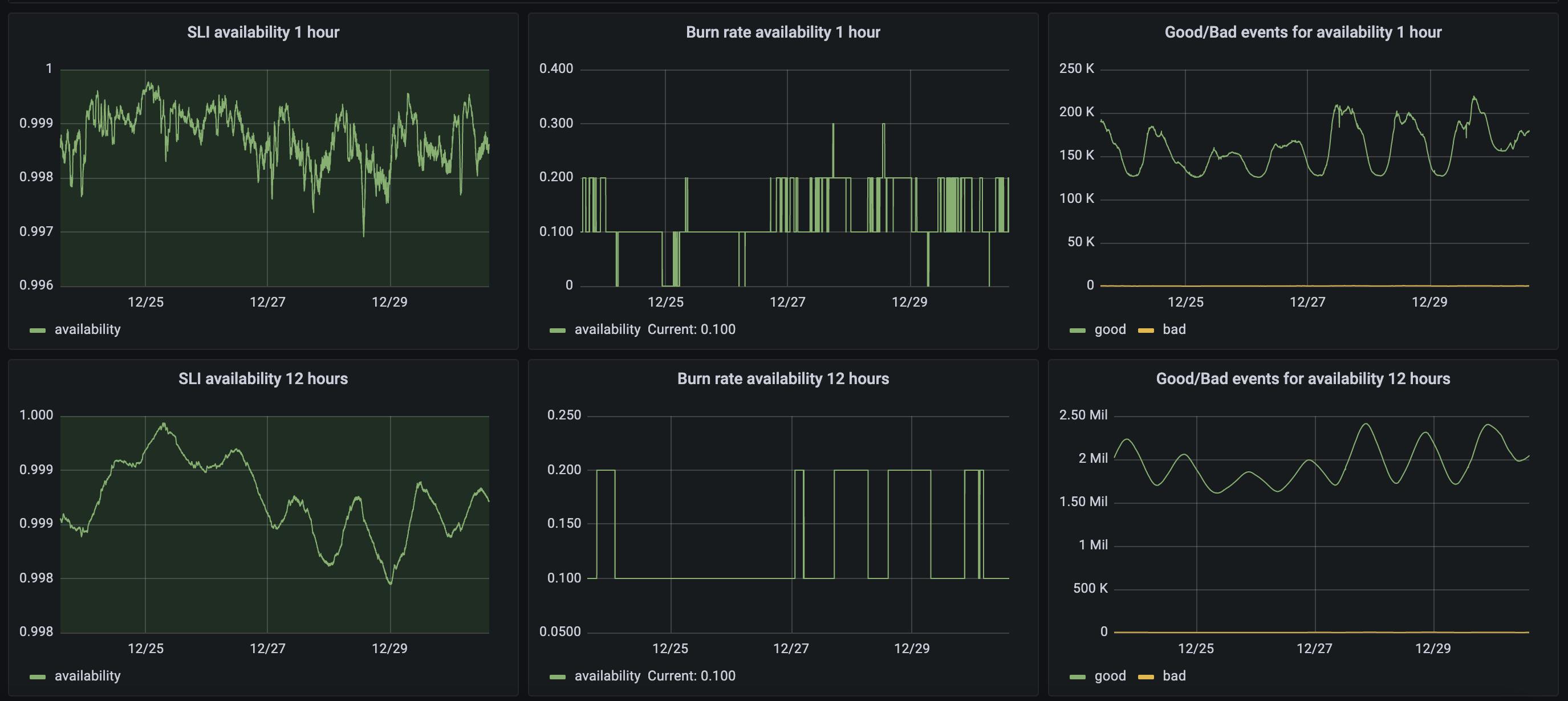
Any action taken around the application environment is to respect your SLA and/or improve your contract. To understand that is everything: imagine you are deploying a new PullRequest to the production environment. Which is then moving 20% of HTTP calls to 400 or 500 (never mind, but it is not 2xx). The time this new version remains online is reducing your uptime (impacting your Error Budget). How long it will take to fix it?
- Are you able to make a rollback?
- Are you able to fix the code and put a new version online?
So with this fail, we can take actions around:
- The code quality, PR review process, non-regression testing, ....
- The CI efficiency: how long is the build? What are the steps auto played? Is there any manual step?
- The CD efficiency: how the application is deployed? Is there any manual step? Is there monitoring checking for problems and auto rollback?
- The production observability
DevOps or SRE target is about the efficiency of our IT. Time to market is important, automation is contributing to it but to be able to automate everything we need to observe our environments.
Dev and SysAdmin are still existing but the job changed over these years. And changed because of the problems I tried to describe to you. There is a part of the IT which is in charge of only one of the two groups, but each other should have at least a limited vision about what is happening in the other part of the world. Working in completely isolated Silos can work, but most of the time we are not fixing the root cause of the problems because nobody is taking care of what is happening in the middle.